Published Date: July 14, 2025 , Written by: Anand Selvadurai , Category: Artificial Intelligence, Machine Learning, Data Annotation

POPULAR POSTS
-
01
Top 10 Companies Offering Software Modernization Consulting Services in 2026
-
02
11 Proven Benefits of AI Chatbots for Businesses in 2025
-
03
How To Improve Document Processing Accuracy Using Document AI
-
04
Top 10 AI Development Companies Offering End-to-End AI Development Services
-
05
What Digital Transformation Means for Businesses in 2026

Data annotation is the process of adding labels to raw data so machines can understand it like humans do. With these labeled data, AI systems can easily learn from examples. You can annotate data of various forms like text, images, videos, or audio files. Each label exactly tells the machine what is in the data. Good labels help AI models learn fast and stay accurate.
Understanding Data Annotation
Data annotation is a detailed process where we make raw data machine readable. Imagine you add sticky notes to a big folder of documents; data annotation is basically the same. Each note explains what’s inside the data. You can do this to all types of data. Images, text, audio, videos.
For example if you give a computer a picture of a dog, it won’t know it’s a dog unless you label it. Once you label that picture “dog” the computer can identify “dog” in the future which is called learning.
If you feed it hundreds or thousands of pictures with different labels like “dog”, “cat” or “car” it starts to recognize patterns. That’s how machine learning works. It learns from the data labels.
Data annotation services work to prepare data for training, also called training data. This training data is what powers AI systems. Without it your AI model would be clueless as it would have no idea what to look for or how to make decisions.
Why Data Annotation is Important for AI and ML
Now think about a self-driving car. It sees the world through cameras and sensors using computer vision technology, but without labeled data, it has no idea what it’s looking at. Data annotation tells the system what each object is, whether it’s a stop sign, a pedestrian or a traffic light.
These labels help the AI learn in real time. It starts to connect what it sees with what it should do. That’s how it learns to slow down, turn or stop. Without this kind of training data, the car can’t make safe decisions. Annotation gives it the context to act like a smart driver.
In other words, for computer vision services to work, data annotation is key.
AI and machine learning indeed relies on data. But having a lot of data wouldn’t do anything. The data must be clean, organized and well-labeled. That’s where annotation comes in.
When you annotate data, you’re giving the model a guide. You can think of it like teaching a student with examples. Let’s say you want to build a chatbot.
For that, you need to label different pieces of text so the model knows what’s a greeting, what’s a question, what’s a complaint and other nuances of human language.
You can say that the quality of your labels affects everything. If the labels are off or confusing, the model will learn the wrong thing which leads to errors. On the other hand, clean and consistent data labeling helps your model learn faster and become smarter.
So, you should label data for the models to work better. It’s rather a popular and convenient choice to outsource data labeling for machine learning models to train and work better.
What are the Types of Data Annotation
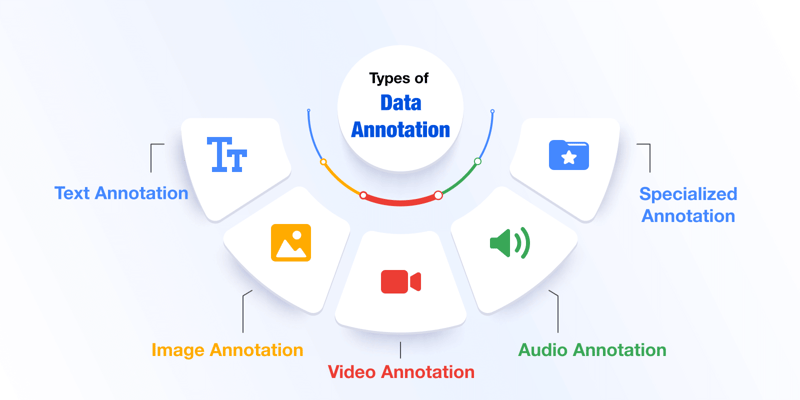
Data annotation is not one size fits all. It varies based on the type of data you’re working with. The way you label text is very different from the way you label images or audio. There are many types of data annotation and here we will see some of them.
1. Text Annotation
Text annotation is about teaching machines to understand written language. At first glance this might seem easy. But human language is layered. We use slang, change meanings based on context and write in different tones, all of which are super complicated for a non-human being to understand. Hence labeling text properly is very important because even a tiny mistake can change the meaning of a sentence altogether.
One common method is named entity recognition. This means identifying people, places, dates or any specific names in a sentence. For example in the sentence “Albert Einstein developed Theory of Relativity” you would label “Albert Einstein” as a person and “Theory of Relativity” as a scientific principle.
Another method is sentiment tagging which tells the system if a piece of text is positive, negative or neutral. For example the sentence “This product is amazing” would get a positive tag. Sentiment tags are used often in customer feedback systems, social media monitoring tools and review platforms to understand the sentiment behind human text.
You can also label text based on intent or topic classification. This is helpful for chatbots or virtual assistants. If someone writes “I need to book a flight” the system should know this is a travel related request. Text annotation is important for large language models and generative AI models to function efficiently.
2. Image Annotation
Image annotation is what lets computers see what's really inside a picture. That's used in everything from face recognition systems to self-driving cars.
At its most basic level, you draw a bounding box around an object in the image. That box might be around a car, a person, a street sign or a traffic signal. The system learns to look inside that box and match it with the right label.
Bounding boxes can be a bit limiting, though. If you're labeling a bicycle, for instance, a box might include a lot of empty space. That's where polygons come in. They allow for tighter, more accurate labeling. A bicycle, for example, is a lot more easily labeled with a polygon than a box.
Semantic segmentation takes that process a step further. Instead of drawing shapes, each pixel in the image gets labeled. That gives you very detailed, very in-depth results.
You see exactly where objects begin and end. That's useful in medical imaging or satellite photos, where knowing that level of detail is crucial.
3. Video Annotation
Video annotation is like image annotation, but for many frames. Each second of video can have 24 or more frames, and every frame might need to be labeled.
One task is frame-by-frame tracking. You follow an object, like a car or a person, across the screen. This is used in sports analytics, surveillance systems and traffic monitoring.
Another task is action recognition. This means labeling actions like running, waving or picking up an item. This type of annotation helps machines understand motion and behavior over time.
4. Audio Annotation
Audio data needs a different approach. Instead of pictures or words, you’re working with sound waves. Machines can’t understand sound on their own, so it needs to be converted into labels they can process.
The most common task is speech-to-text annotation. You label each word someone says in a clip. This is used in virtual assistants, transcription software and call center analysis.
Another method is speaker diarization. This means figuring out who is speaking and when. You don’t just want to know what was said but also want to know who said it. This is useful in meetings, interviews and podcasts.
Sometimes audio annotation involves labeling emotions or background sounds. For example in a customer service call you might mark laughter, frustration or silence.
5. Specialized Annotation
Some industries use unique forms of annotation based on their needs.
In healthcare, radiologists label medical scans. These labels help AI detect tumors, broken bones, or other health issues. Accuracy here is extremely important because it can affect real-life decisions.
In autonomous driving, cars need to recognize everything around them, lanes, signs, pedestrians, other cars. The images and videos captured by cameras must be carefully labeled to train the driving system.
In e-commerce, product images need to be labeled with tags like color, type, or brand. This helps power visual search, recommendation systems, and inventory tools.
The Data Annotation Process
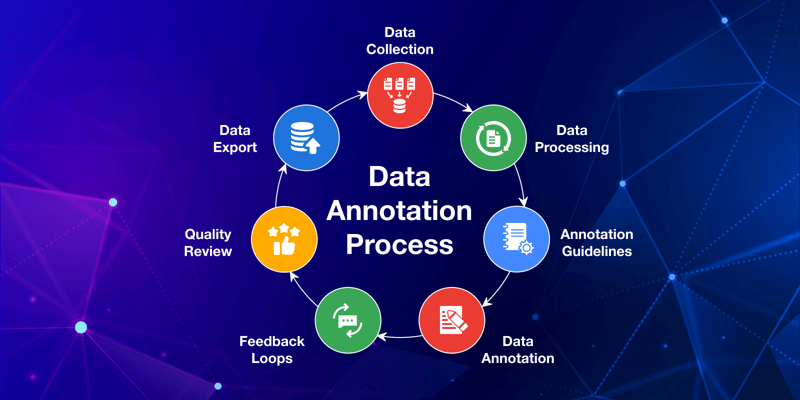
It is not a one-step task to create high-quality labeled data, but rather, it follows a clear process that helps teams stay organized and ensures that the final dataset is accurate. Let us look at how the data annotation process works, step by step.
1. Requirement Gathering
Before any data gets labeled, you need to set the rules. This step is all about understanding what you’re trying to achieve. You define what each label means, what classes or categories exist, and how edge cases should be handled.
This helps annotators know what to do in tricky situations. Clear instructions make everything smoother later. Without this, people will guess or label things differently, which can confuse your AI model.
- Create a list of classes or labels to use.
- Describe edge cases and how to handle them.
- Write clear guidelines with real examples.
2. Pilot Labeling and Feedback Loops
Once your guidelines are ready, it’s time to test them. You start by labeling a small set of data. This is your trial run. The goal is to check if the instructions are clear and if annotators are following them correctly.
You also see where people get confused. Based on what you learn, you update the guidelines. This feedback loop helps catch mistakes early before labeling the full dataset.
- Label a small sample to test the process.
- Collect feedback from annotators and reviewers.
- Improve instructions based on real use.
3. Full-Scale Annotation
Now that the process is tested, you can scale up. This means labeling large volumes of data. You can use in-house teams, hire a managed service, or rely on crowdsourcing platforms. Each option has pros and cons.
In-house teams offer better control. Managed services bring experience and tools. Crowdsourcing is often cheaper and faster, but quality can vary. It’s important to pick the right setup for your needs.
- Choose between in-house, managed, or crowdsourced teams.
- Use tools to manage workflows and monitor progress.
- Keep communication open to address any issues.
4. Quality Review and Iteration
The job doesn’t end after labeling. You still need to check the quality. This step is where reviewers look for errors and inconsistencies. One popular method is measuring how much different annotators agree.
If two people label the same data in different ways, that’s a problem. You want to see strong agreement. Based on these reviews, you may relabel some data or update your guidelines again. Quality review is ongoing, not a one-time task.
- Use agreement scores to measure label consistency.
- Review samples regularly for errors or confusion.
- Keep improving guidelines based on what you find.
What are the Leading Data Annotation Tools & Platforms
The data annotation method involves a plethora of tools, and some of which are open-source and some are commercial. Others are made for special tasks in areas like healthcare or maps. Each tool is built with a purpose.
According to Grand View Research, the global data annotation tools market size is estimated to grow at a CAGR of 26.3% from 2024 to 2030.
For effective artificial intelligence services, it is important to choose the right tools, which highly depends on your project, your team, and the kind of data you're working with. Let’s take a closer look.
1. Open-Source Solutions
If you are a beginner, you can start with open-source tools that are free to use. They’re built by communities or research labs. Many teams use them to build custom workflows.
These tools give you more control. You can modify the code to fit your needs. But they often need more setup time and some technical skill.
CVAT (Computer Vision Annotation Tool) is one of the most popular options. It was built by Intel and is made for labeling video and image data. It supports many formats and comes with a clean interface. You can assign tasks, track progress, and even use pre-trained models to speed up the process.
LabelImg is a lightweight tool for drawing bounding boxes in images. It’s simple and quick to use. You can export labels in common formats like XML or YOLO.
VGG Image Annotator (VIA) is a web-based tool. You don’t need to install anything. Just run it in your browser. It works well for small projects or personal experiments.
Key features of open-source tools:
- No license fees or subscription costs
- Full control over customization
- Good choice for small to mid-sized teams with technical skills
2. Commercial Platforms
Commercial tools are designed for scale. They come with support, automation, and team management features. Many offer AI assistance, which helps speed up annotation. These tools are popular among large companies and AI startups that work with big datasets.
Labelbox is one of the most well-known commercial tools. It supports image, text, audio, and video labeling. What makes it stand out is the ability to manage large teams. It also includes features like automated labeling, review workflows, and model performance tracking. You can build a full pipeline within one platform.
SuperAnnotate is another powerful tool. It focuses on combining human labelers with AI. You can set up pipelines that let the AI label easy parts first. Then humans can fine-tune or review the results. This mix helps speed up projects and cut costs. The platform also includes collaboration tools for large teams.
Key features of commercial platforms:
- Easy to scale with large datasets and teams
- AI-assisted labeling for faster results
- Built-in quality checks and feedback loops
3. Niche and Vertical-Specific Tools
Some tools are built for very specific industries. These tools understand the special needs of that domain. They often include extra features that general tools don’t offer.
MD.ai is built for the medical field. Doctors and radiologists use it to annotate X-rays, MRIs, and CT scans. It supports complex workflows like DICOM viewing and HIPAA compliance. This makes it ideal for training AI in healthcare.
DocTR is made for document processing. It works well with scanned PDFs and printed forms. You can use it to label blocks of text, tables, and handwritten notes. This helps in training OCR models for finance, insurance, or legal sectors.
Geospatial tools are used in mapping projects. These platforms allow you to label satellite images, identify roads, track changes in land use, or spot buildings. They are popular in agriculture, defense, and disaster response.
Key features of niche tools:
- Designed with industry-specific needs in mind
- Supports data formats unique to each domain
- Offers expert-level control and compliance features
Use the right annotation tool because it can save time and improve your model’s accuracy. Some teams start with open-source tools. Others go straight for commercial or domain-specific platforms. The best tool is the one that fits your team and your project goals.
Best Practices for High‑Quality Annotation
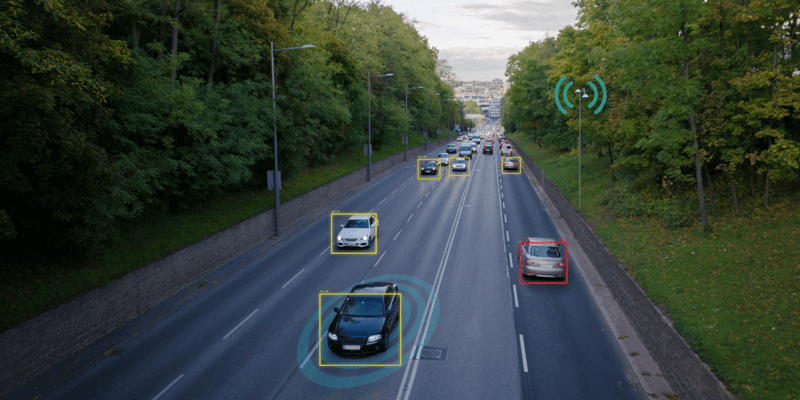
It takes a lot to derive the best results for quality data annotation. You need a robust process that keeps things consistent. Here are some practical tips that make a big difference.
1. Clear Guidelines
Remember to give strong set of instructions as they are important for every annotation project because these guidelines tell data labelers what to do. They should include examples and edge cases. When people can see good and bad examples, they make fewer mistakes. Additionally, visuals and style guides help clear up confusion.
- Add sample images or text for each label
- Include edge cases and explain how to handle them
- Create a style guide everyone can follow
2. Continuous Training and Calibration
Regular feedback is highly important and even skilled annotators need it. As the project grows, things change. New edge cases show up. Teams must meet often to talk about what’s working and what’s not. In such a dynamic environment, feedback and calibration help everyone stay on the same page.
- Hold weekly review or check-in meetings
- Use sample tasks for team-wide calibration
- Answer questions live to avoid confusion
3. Leveraging AI-Assisted Labeling
With the rise of artificial intelligence services, you don’t have to do everything by hand. Many tools offer AI-powered help. These features can make early suggestions or pre-label the data, and all you have to do is to just review and adjust it. This makes things faster and helps you scale.
- Use pre-labeling tools to get a head start
- Set up active learning loops to improve with feedback
- Save time by skipping easy or repetitive labels
4. Scalability and Cost Management
As projects grow, you need to control costs without, but it should not hinder quality. This means you have got to plan ahead. You want to know how much data needs labeling, how fast it should move, and how many people you need. With a good setup, you can balance speed, cost, and accuracy.
- Estimate how much annotation your project really needs
- Mix automation and human review to save time
- Track costs and adjust your setup as you go
Common Challenges & Solutions
Every data annotation project faces a few bumps along the way, which is normal and unavoidable. The key is knowing what to expect and how to deal with it. Let’s walk through some of the most common challenges teams run into and what they can do to fix them.
Bias and Consistency Issues
One of the biggest problems in annotation is human bias. For effective machine learning services, quality and unbiased data is highly critical. Everyone sees data in their own way. What one person labels as “positive,” another might call “neutral.”
This creates noise in your dataset. Over time, this makes the model learn the wrong patterns. The issue gets worse when multiple annotators label the same type of data but don’t follow the same logic. The result is inconsistent labels that confuse the AI system.
The best way to solve this is with strong training and clear rules. Start with detailed guidelines. Add examples that show what’s right and what’s not. Then, hold review sessions often. Let annotators ask questions and clear up confusion.
You can also use agreement scores to check how much the team is aligned. When scores are low, stop and reset. Talk about the gaps and update your instructions. Doing this often keeps everyone on track and reduces bias over time.
Data Security and Privacy
Data security is a serious concern, especially when working with sensitive content. Many datasets include personal details like names, addresses, emails, or even health records. If this information leaks, it can cause real hindrance. That’s why you must keep your annotation process safe.
However, you can follow safety practices like removing personal data before sending it to annotators. This step is called data anonymization. You can blur faces in images, redact names in text, or mask numbers in forms.
Then, make sure the annotation happens in a secure environment. Use access controls. Limit who can see what. Some teams use VPNs, password-protected portals, or private servers. Also, train your annotators on privacy rules.
When people understand the risks, they tend to be more careful with data. Always ensure your systems and network are safe. You can also rely on robust cybersecurity services to insulate your digital environment from any cyber threats.
Managing Complex Annotation Schemas
Sometimes, annotation is beyond simple. You might need to use many labels at once. In a text file, one sentence could be “positive” and “sarcastic” at the same time. In an image, an object could belong to two categories.
You may even need to build labels in a hierarchy, like “vehicle” > “car” > “sports car.” These cases need a more structured setup. If you don’t manage it well, the labels can overlap or contradict each other.
To handle this, use the right tools. Some platforms are built to support complex schemas. They let you layer labels, create nested classes, and spot overlaps easily. You should also break down the work into small steps.
Let annotators focus on one type of label at a time. This makes things easier to manage and helps reduce mistakes. Lastly, use frequent testing. Run small batches and check the output. This helps catch problems early before they grow too large.
Way Forward
Data annotation is the quiet engine behind every smart AI system because it gives meaning to raw data. Without it, even the most advanced model won’t work right.
If you are just getting started, try to run a pilot project, then pick a small dataset and test your approach. This helps you clearly understand what works and what doesn’t.
Once that’s in place, choose a tool that fits your unique requirements. It could be open-source, commercial, or industry-specific. Just make sure it’s easy to use and can grow with your needs.
One important thing to remember is to set up quality checks from day one. Define clear guidelines. Train your annotators. Review the labels often. Use feedback to make things better. That’s how you keep your data clean and useful.
Data annotation is a process. It takes time, focus, energy, and the right setup. But once you get it right, your AI models become much more efficient and accurate.

Tech.us
Tech.us is an AI development company that builds custom AI solutions for businesses seeking measurable results. We partner with organizations to design, develop, and deploy scalable AI systems that solve complex challenges and unlock new opportunities for growth. Our team delivers practical AI applications that create tangible business impact across industries.
1,500+
Projects
Delivered
Delivered
25+
Years in
Business
Business
30+
Industries
Served
Served
100%
Commitment
to Success
to Success
WRITTEN BY



Get Free Tips
NEWSLETTER
Get Free Tips
Submit to our newsletter to receive exclusive stories delivered to vou inbox!
Thanks for submitting the form.
RECENT POSTS

When Should Businesses Build AI Into Custom Software?

10 Leading AI Consulting Partners for 2026

How to Identify High-ROI AI Automation Opportunities in Your Business

91% of AI Models Degrade Over Time: How Businesses Can Prevent Performance...

7 Enterprise AI Security Risks That Could Derail Your AI Initiative – And...